Cloud Foundry overview
Page last updated:
This topic tells you about Cloud Foundry and how it works.
Introduction to Cloud Platforms
Cloud platforms enable rapid deployment of applications and services, making them globally accessible within minutes. When application requests increase, cloud infrastructure can automatically scale to meet higher demand, eliminating traditional build-outs and migrations. This approach allows developers to focus on applications and data without the need to manage underlying infrastructure.
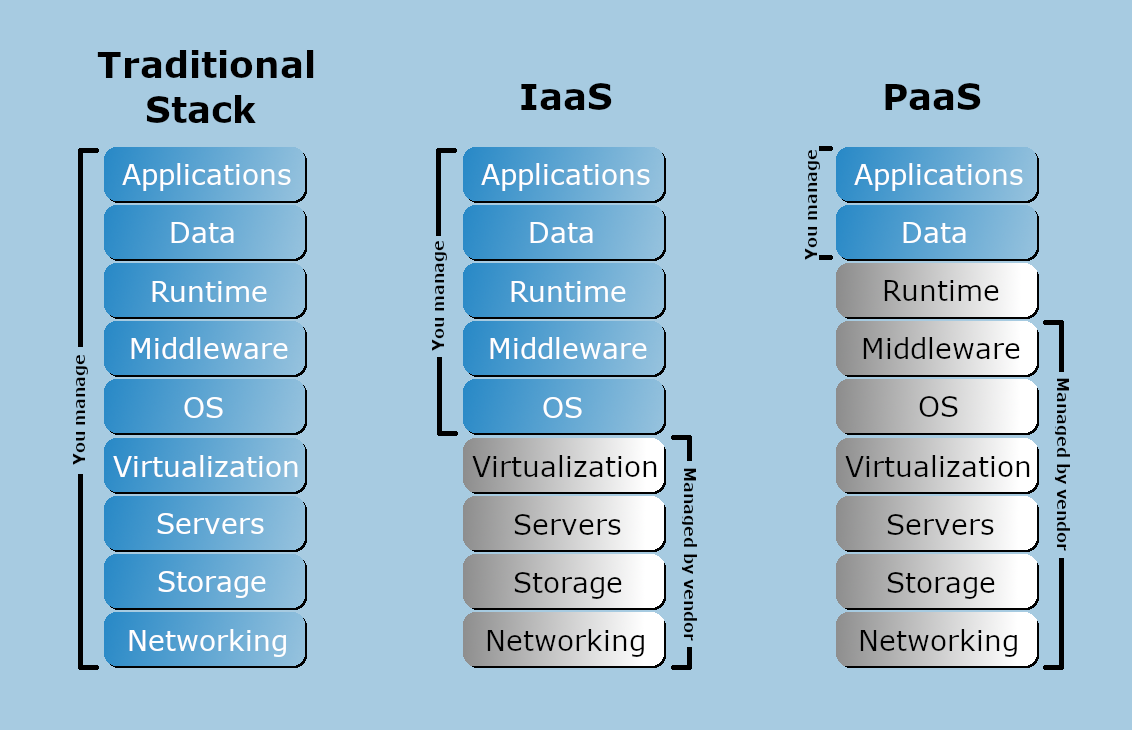
The following diagram illustrates the layers of a typical technology stack, comparing the traditional IT model with an IaaS stack and a PaaS stack, showing which layers are managed by users vs. providers.
Traditional IT Stack: All layers are managed in-house, including applications, data, runtime, middleware, OS, virtualization, servers, storage, and networking.
IaaS Stack: The provider manages the servers, storage, networking, and virtualization, while the user manages applications, data, runtime, middleware, and OS.
PaaS Stack: The provider manages all layers except for applications and data, which remain the user’s responsibility.
View a larger version of this diagram.
{kind=link}
About Cloud Foundry
This section describes why Cloud Foundry is an industry-standard cloud platform.
Not all cloud platforms are created equal. Some have limited language and framework support, lack key app services, or restrict deployment to a single cloud.
As an industry-standard cloud platform, Cloud Foundry offers the following:
Open source code: The platform’s openness and extensibility prevent its users from being locked into a single framework, set of app services, or cloud. For more information, see the Cloud Foundry project on GitHub.
Deployment automation: Developers can deploy their apps to Cloud Foundry using their existing tools and with zero modification to their code.
Flexible infrastructure: You can deploy Cloud Foundry to run your apps on your own computing infrastructure, or deploy on an IaaS like vSphere, AWS, Azure, GCP, or OpenStack.
Commercial options: You can also use a PaaS deployed by a commercial Cloud Foundry cloud provider. For more information, see Cloud Foundry Certified Platforms.
Community support: A broad community contributes to and supports Cloud Foundry. See Welcome to the Cloud Foundry Community.
Cloud Foundry is ideal for anyone interested in removing the cost and complexity of configuring infrastructure for their apps.
How Cloud Foundry Works
To flexibly serve and scale apps online, Cloud Foundry has subsystems that perform specialized functions. The following sections describe how some of these main subsystems work.
Load balancing
This section describes how Cloud Foundry handles load balancing.
Clouds balance their processing loads over multiple machines, optimizing for efficiency and resilience against point failure. A Cloud Foundry installation accomplishes this using the following components:
BOSH creates and deploys VMs on top of a physical computing infrastructure, and deploys and runs Cloud Foundry on top of this cloud. To configure the deployment, BOSH follows a manifest document. For more information, see the BOSH documentation.
Cloud Controller runs the apps and other processes on the cloud’s VMs, balancing demand and managing app lifecycles. For more information, see Cloud Controller.
The Gorouter routes incoming traffic from the world to the VMs that are running the apps that the traffic demands, usually working with a customer-provided load balancer. For more information, see Cloud Foundry Routing Architecture.
Running apps
This section describes the VMs that run your apps in Cloud Foundry and how the platform packages your apps to run on these VMs.
VMs in Cloud Foundry
Cloud Foundry designates the following types of VMs:
- Component VMs make up the platform’s infrastructure.
- Host VMs host your apps for the outside world.
Within Cloud Foundry, the Diego system distributes the hosted app load over all of the host VMs, and keeps it running and balanced through demand surges, outages, or other changes. Diego accomplishes this through an auction algorithm.
For more information, see Diego Components and Architecture.
Distributing apps
To meet demand, multiple host VMs run duplicate instances of the same app. This means that apps must be portable. Cloud Foundry distributes app source code to VMs with everything the VMs need to compile and run the apps locally.
Cloud Foundry includes the following with your app’s source code:
- Stack: the operating system the app runs on.
- Buildpack: contains all languages, libraries, and services that the app uses.
Before sending an app to a VM, the Cloud Controller stages it for delivery by combining the stack, buildpack, and source code into a droplet that the VM can unpack, compile, and run. For simple, standalone apps with no dynamic pointers, the droplet can contain a pre-compiled executable instead of source code, language, and libraries.
For more information, see:
Organizing users and workspaces
This section describes how Cloud Foundry organizes users and workspaces.
Cloud Foundry manages user accounts through two User Account and Authentication (UAA) servers, which support access control as OAuth2 services and can store user information internally, or connect to external user stores through LDAP or SAML.
For more information, see User Account and Authentication (UAA) Server.
The following table describes what the two UAA servers do:
| Server | Purpose |
|---|---|
| First UAA server |
|
| Second UAA server |
|
For more information, see Orgs, Spaces, Roles, and Permissions.
Storing resources
The following table describes where Cloud Foundry stores resources:
| Resource | Storage Location |
|---|---|
|
GitHub |
|
Internal or external blobstore |
|
MySQL |
Communicating with components
This section describes how Cloud Foundry components communicate with one another.
Cloud Foundry components communicate in the following ways:
- By sending messages internally using HTTP and HTTPS protocols
- By sending NATS messages to each other directly
BOSH Director co-locates a BOSH DNS server on every deployed VM. All VMs keep up-to-date DNS records for all the other VMs in the same foundation. This enables service discovery between VMs.
BOSH DNS allows deployments to continue communicating with VMs even when the VMs’ IP addresses change. It also provides client-side load balancing by randomly selecting a healthy VM when multiple VMs are available.
For more information about BOSH DNS, see Native DNS Support in the BOSH documentation.
Monitoring and Analyzing
This section describes logging in Cloud Foundry.
Cloud Foundry generates system logs from Cloud Foundry components and app logs from hosted apps. As Cloud Foundry runs, its component and host VMs generate logs and metrics. Cloud Foundry apps also typically generate logs.
The following table describes where Cloud Foundry sends logs:
| Log Type | Destination |
|---|---|
| Cloud Foundry component logs | Rsyslog agents |
| Cloud Foundry component metrics | Loggregator |
| App logs | Loggregator |
Component logs stream from rsyslog agents, and the cloud operator can configure them to stream out to a syslog drain.
The Loggregator system aggregates the component metrics and app logs into a structured, usable form, the Firehose. You can use all of the output of the Firehose, or direct the output to specific uses, such as monitoring system internals, triggering alerts, or analyzing user behavior, by applying nozzles.
For more information, see Loggregator Architecture.
Using services
This section describes how you can use services with your apps on Cloud Foundry.
Typical apps depend on free or metered services such as databases or third-party APIs. To incorporate these into an app:
Write a Service Broker: This component manages the life cycle of the service. The Service Broker uses the Service Broker API to advertise a catalog of service offerings to Cloud Foundry apps.
Provision the Service Instance: Create an instance of the service offering by sending a provision request to the Service Broker API.
Enable apps to access the Service Instance: Configure the Cloud Foundry app to make calls to the Service Instance using the Service Broker API.
For more information, see Services.
Create a pull request or raise an issue on the source for this page in GitHub