BOSH Backup and Restore Developer's Guide
Page last updated:
This guide describes the framework for release authors to add backup and restore functionality to their release by using BOSH Backup and Restore (BBR).
BBR is a framework for backing up and restoring BOSH deployments and BOSH Directors. BBR triggers the backup or restore process on the deployment or BOSH Director and transfers the backup artifacts to and from the deployment or BOSH Director.
The BBR framework consists of a command line interface (CLI) and a set of hooks, which call out to scripts. The framework uses BOSH to orchestrate the execution of backup and restore scripts. BBR allows release authors fine-grained control over how their release is backed up.
Backup mechanism
Different systems require different strategies for backup and restore. To help release authors make consistent backups of their systems, the BBR framework provides hooks to lock scripts that bring a job to a consistent state before backup begins.
The following diagram illustrates an example BBR script execution sequence.
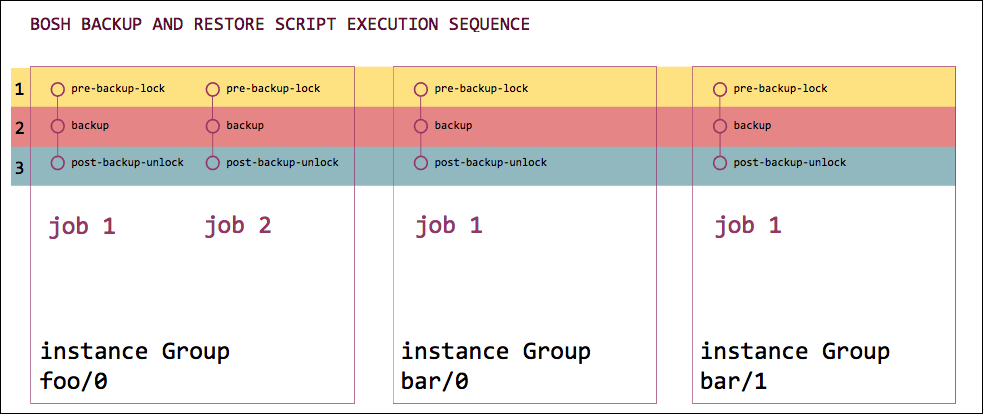
The diagram shows a deployment that has two instance groups. Group foo contains instance foo/0, which contains jobs 1 and 2. Group bar contains instances bar/0 and bar/1, each of which contains job 1.
- Stage 1 starts: all pre-backup-lock scripts run for all jobs in all instance groups. Stage 1 ends.
- Stage 2 starts: all backup scripts run for all jobs in all instance groups. Stage 2 ends.
- Stage 3 starts: all post-backup-lock scripts run for all jobs in all instance groups. Stage 3 ends.
There is no fixed order in which BBR calls the scripts within each stage.
Because the framework is focused on the interface, hooks, backup destination, and intra-deployment orchestration, it is mechanism-agnostic. Release authors can back up their release however they want to, as long as the scripts they write have the correct name and directory structure.
To ensure that backup and restore scripts do not get out of sync with the releases themselves, release authors are responsible for naming, creating, testing, and troubleshooting their own backup and restore scripts.
Note For all releases, these backup and restore jobs might be co-located with those of other releases. Therefore, release authors must give these jobs unique and descriptive names to avoid name collisions.
Script organization
BBR sets out a contract with release authors to call designated backup and restore
scripts under the /var/vcap/jobs/JOB-NAME/bin/bbr/SCRIPT-NAME directory:
- Backup script names
pre-backup-lockbackuppost-backup-unlock
- Restore script names
pre-restore-lockrestorepost-restore-unlock
- Metadata script name (if needed)
metadata
For example, the directory structure of a templated BBR job looks like the below:
/var/vcap/jobs/bbr-uaadb/bin/bbr/backup/var/vcap/jobs/bbr-uaadb/bin/bbr/post-restore-unlock
Release authors must implement scripts as part of the BBR contract. Package and distribute the scripts as part of your BOSH release. The Exemplar Backup and Restore Release in GitHub provides examples of how release authors can structure their jobs to implement the contract with BBR.
The BBR CLI can remotely locate and run the scripts, even if they are located on different VMs. For example, the lock/unlock scripts can be located on release VMs while, due to disk-space constraints, the backup/restore scripts are co-located on a separate backup-restore VM.
Scripts are executed in a specific order.
For the backup workflow, the order is pre-backup-lock, backup, and then post-backup-unlock.
For the restore workflow, the order is pre-restore-lock, restore, and then post-restore-unlock.
All scripts should be executable scripts. ERB tags can be used for templating.
These scripts are executed similarly to other release job scripts, such as start, stop, or drain, and you can use the job’s package dependencies.
BBR checks exit codes of the scripts when orchestrating.
Exit code 0 indicates success, and any other exit code indicates a failure.
Directory structure of a BOSH release with BBR scripts
The following is an example directory structure of a BOSH release that includes BBR scripts.
acme-release
├── README.md
├── config
│ ├── blobs.yml
│ └── final.yml
├── jobs
│ ├── bbr-acmedb
│ │ ├── monit
│ │ ├── spec
│ │ └── templates
│ │ ├── backup.sh.erb
│ │ ├── config.json.erb
│ │ └── restore.sh.erb
│ └── bbr-lock-unlock-acme
│ ├── monit
│ ├── spec
│ └── templates
│ ├── post-backup-unlock.sh.erb
│ ├── pre-backup-lock.sh.erb
│ └── metadata.sh.erb (optional)
├── packages
└── src
Script ordering across jobs
During the backup workflow, all pre-backup-lock scripts are invoked before the backup scripts on all of the jobs in the deployment.
All backup scripts are invoked before the post-backup-unlock scripts on all of the jobs in the deployment.
Note
Both the pre-backup-lock and post-backup-unlock are called in parallel while respecting the locking order constraints.
During the restore workflow, all pre-restore-lock scripts are invoked before the restore scripts on all of the jobs in the deployment.
All restore scripts are invoked before the post-restore-unlock scripts on all of the jobs in the deployment.
By default pre-backup-lock and pre-restore-lock scripts from different jobs are invoked in an arbitrary order.
You can specify an order for lock scripts from specific jobs in the metadata script.
The post-backup-unlock and post-restore-unlock scripts from different jobs are invoked in an arbitrary order
when no locking dependency is specified, or the opposite order of lock scripts as stated in metadata scripts.
When a job specifies locking dependency to a job that does not exist in the current deployment, BBR ignores that dependency.
For more information, see Metadata script below.
Logs
The stdout and stderr streams are captured and sent to the operator who invokes the backup and restore.
Note
Release authors should avoid printing sensitive information to stdout or stderr.
BBR prints any output from the scripts in case of failure. Ensure your script does not print any sensitive data, such as credentials.
In particular, if you are using set -x in your script, add set +x before you use any credentials.
Backup workflow
pre-backup-lock
The release job can have a pre-backup-lock script that stops any processes that could make changes to the components being backed up.
This script must allow the job to lock so that backups are consistent across a cluster.
For example, in a Cloud Foundry deployment, the pre-backup-lock script stops Cloud Controller processes
that might make changes to its blobstore and database. This ensures the blobstore and the Cloud Controller database are consistent with each other.
Job configuration
To add a pre-backup-lock script to a job:
- Create a script with any name in the templates directory of your job.
-
In the templates section of the release job spec file, add the script name and
bin/bbr/pre-backup-lockas a key-value pair. For example:--- name: lock-unlock-acme templates: pre-backup-lock.sh.erb: bin/bbr/pre-backup-lock
-
If you want your
bin/bbr/pre-backup-lockscripts to run in a specific order, define that order using the optional metadata script. In the sample directory structure illustrated above, this script is calledmetadata.sh.erb.
a. The metadata script specifies that the current job must be locked before some other job(s) in the deployment. When run, this script must print a YAML file to stdout. For example:#!/usr/bin/env bash echo "--- backup_should_be_locked_before: - job_name: lock-unlock-acme release: acme-release"
b. Add an entry to the templates section of the release job spec file:templates: ... metadata.sh.erb: bin/bbr/metadata
See Metadata script below for information about the properties you can use in this script.
Backup
The release job can have a backup script that dumps the backup of the job’s database to the directory specified by $BBR_ARTIFACT_DIRECTORY. For example, when backing up MySQL, this script can invoke the mysqldump binary for the MySQL adapter.
There must be at least one job in the deployment providing a backup script. If there is no backup script, calling backup or pre-backup-check for the deployment fails.
Job configuration
To add a backup script to a release job:
- Create a script with any name in the templates directory of a release job.
In the templates section of the release job spec file, add the script name and
bin/bbr/backupas a key-value pair. For example:--- name: backup-restore-acme templates: backup.erb: bin/bbr/backup
post-backup-unlock
The backup and restore job can have a post-backup-unlock script that undoes the operations performed by pre-backup-lock.
Job configuration
To add a post-backup-unlock script to a release job:
- Create a script with any name in the templates directory of a release job.
In the templates section of the release job spec file, add the script name and
bin/bbr/post-backup-unlockas a key-value pair. For example:--- name: lock-unlock-acme templates: post-backup-unlock.erb: bin/bbr/post-backup-unlock
Error handling during backup
If errors occur during the backup workflow, cleanup tasks are executed to put the system back in a working state.
A normal workflow for backing up a deployment does the below:
Restore workflow
pre-restore-lock
The release job can have a pre-restore-lock script that stops any processes that could make changes to the components being restored. This script must allow the job to lock so that restorations are consistent across a cluster.
Job configuration
To add a pre-restore-lock script to a job:
Create a script with any name in the templates directory of your job.
In the templates section of the release job spec file, add the script name and
bin/bbr/pre-restore-lockas a key-value pair. For example:--- name: lock-unlock-acme templates: pre-restore-lock.sh.erb: bin/bbr/pre-restore-lockIf you want your
bin/bbr/pre-restore-lockscripts to run in a specific order, define that order using the optional metadata script. In the sample directory structure illustrated above, this script is calledmetadata.sh.erb.
Thepre-restore-lockscripts are called before anyrestorescripts have been called. Success indicates the job is ready to be restored.a. The metadata script specifies that the current job must be locked before some other job(s) in the deployment. When run, this script must print a YAML file to stdout. For example:
#!/usr/bin/env bash echo "--- restore_should_be_locked_before: job_name: lock-unlock-acme release: acme-release"b. Add an entry to the templates section of the release job spec file:
templates: ... metadata.sh.erb: bin/bbr/metadataSee Metadata script below for information about the properties you can use in this script.
Restore
If a release has a backup script, it should also have a restore script. The restore script expects a backup artifact to be provided in $BBR_ARTIFACT_DIRECTORY. For example, when restoring MySQL, the script invokes mysql to restore from a mysqldump file.
Job configuration
To add a restore script to a release job:
- Create a script with any name in the templates directory of a release job.
In the templates section of the release job spec file, add the script name and
bin/bbr/restoreas a key-value pair. For example:--- name: backup-restore-acme templates: restore.erb: bin/bbr/restore
post-restore-unlock
The release job can have a post-restore-unlock script that resumes normal service operation. post-restore-unlock should be idempotent because it can be called multiple times even if pre-restore-lock has not been not called.
Job configuration
To add a post-restore-unlock script to a release:
- Create a script with any name in the templates directory of your job.
In the templates section of the release job spec file, add the script name and
bin/bbr/post-restore-unlockas a key-value pair. For example:--- name: lock-unlock-acme templates: post-restore-unlock.sh.erb: bin/bbr/post-restore-unlock
Error handling during restore
If errors occur during the restore workflow, cleanup tasks are executed to put the system back in a working state.
A normal workflow for restoring a deployment does the below:
(Optional) Metadata script
The metadata script is an optional script that bbr executes before
any other scripts to get more information about the jobs, for example,
locking dependencies and whether the BBR job is enabled or not.
The script is expected to print a yaml on standard out with more information
about the job for backup and restore.
Job configuration
To add a metadata script to a release job:
- Create a script with any name in the templates directory of a release job.
In the templates section of the release job spec file, add the script name and
bin/bbr/metadataas a key-value pair. For example:--- name: backup-restore-acme templates: metadata.erb: bin/bbr/metadata
(Optional) Properties
backup_should_be_locked_before
Use this property to specify the locking dependencies for the current job during backup. The jobs are specified as an array with their release names.
For example:
#!/usr/bin/env bash echo "--- backup_should_be_locked_before: - job_name: lock-unlock-acme release: acme-release"
restore_should_be_locked_before
If you want your bin/bbr/pre-restore-lock scripts to run in a
specific order, define that order using the metadata script, as above, but with
the restore_should_be_locked_before key.
For example:
#!/usr/bin/env bash echo "--- restore_should_be_locked_before: - job_name: lock-unlock-acme release: acme-release"
skip_bbr_scripts
Use this property to disable a BBR job. When the metadata script is templated with this property set to true, the BBR CLI does not run the BBR scripts in this job.
For example:
#!/usr/bin/env bash echo "--- skip_bbr_scripts: true"
Testing
The functional testing pattern recommended for BBR scripts is:
- Create data for which the release is responsible.
- Back up the release.
- Delete data.
- Restore the release.
- Validate that restored data are correct.
Where scripts are implemented for releases that are part of larger deployments, you should perform end-to-end testing that validates consistency across releases.
Backup and restore utilities
If your release stores state in a Postgres or MySQL database, deploy the database-backup-restorer job from the backup-and-restore-sdk-release GitHub repository.
Ensure your job templates a config.json as follows:
{
"username": "db user",
"password": "db password",
"host": "db host",
"port": "db port",
"adapter": "bbr supported adapter (e.g. mysql or postgres)",
"database": "database name"
}
Ensure your backup and restore scripts call the appropriate database-backup-restorer binaries as follows:
Backup
/var/vcap/jobs/database-backup-restorer/bin/backup /path/to/config.json
cp <output_file> $ARTIFACT_DIRECTORY
Restore
cp $ARTIFACT_DIRECTORY <output_file>
/var/vcap/jobs/database-backup-restorer/bin/restore /path/to/config.json
BBR and Cloud Foundry databases
Important
Release authors must ensure the following.
For CF Releases, Your scripts must respect the release_level_backup job property so the scripts run if set to true, but do nothing if set to false.
BBR provides a pattern for Cloud Foundry release authors that ensures their scripts abide by the BBR Framework contract.
A Cloud Foundry operator adds a backup-restore instance to their Cloud Foundry deployment. By default, release-specific database backup and restore job scripts are co-located on this instance along with the database-backup-restorer job from the backup-and-restore-sdk-release GitHub repository.
If your release requires that you stop your component’s processes during backup and restore, you also need to provide unlock and lock scripts. You can co-locate these scripts on either the backup-restore instance or your component’s instance. You should co-locate these scripts on the component’s instance if you want to interact directly with monit or your running job.
More information about unlock and lock scripts are below.
Naming recommendations
When Cloud Foundry is deployed, multiple backup and restore scripts are co-located on the
backup-restore instance, separated by job name.
For this reason, the job names for each release should have a consistent format
so that there is no confusion between BBR jobs.
The recommendations for job names are as follows:
- Use the prefix
bbr-to show that the job is bbr-related - Include the name of the component that is being backed up
For example, you have a release named acme-release that has a
database (db) that must be backed up.
The recommended BBR job name for this database is bbr-acmedb.
This follows the format bbr-RELEASE-NAMEdb.
Example
Acme Release is a Cloud Foundry component that has no persistent disk on its component VM. The release is an API that stores its data in a MySQL database deployed on a different instance group in this CF deployment.
The release authors have chosen to create two new jobs to be incorporated into
their existing release; one job includes the backup and restore scripts in
its templates directory, and the other job includes the pre-backup-lock and
post-backup-unlock scripts.
This is because the operator co-locates the former job on the backup-restore
VM and the latter job on the Acme Release VM.
Here is how the backup and restore job should be placed:
Acceptance tests
The Disaster Recovery Acceptance Test Suite (DRATs) runs against a Cloud Foundry deployment to ensure that backup and restore works as expected.
For more information and instructions for how to run DRATs, see disaster-recovery-acceptance-tests in GitHub.
Create a pull request or raise an issue on the source for this page in GitHub