How Diego balances app processes in Cloud Foundry
Page last updated:
Diego balances app processes over the virtual machines (VMs) in a Cloud Foundry installation using the Diego Auction. When new processes need to be allocated to VMs, the Diego Auction determines which ones must run on which physical machines. The auction algorithm balances the load on VMs and optimizes app availability and resilience. This topic explains how the Diego Auction works.
For more information, see Diego Components and Architecture and the Auction repository on GitHub.
Tasks and long running processes
Diego Auction distinguishes between two types of jobs: Tasks and Long-Running Processes (LRPs).
Tasks run once, for a finite amount of time. A common example is a staging task that compiles an app’s dependencies, to form a self-contained droplet that makes the app portable and runnable on multiple VMs. Other examples of tasks include making a database schema change, bulk importing data to initialize a database, and setting up a connected service.
Long-Running Processes run continuously, for an indefinite amount of time. LRPs terminate only if they crash or are stopped. Examples include web servers, asynchronous background workers, and other applications and services that continuously accept and process input. To make high-demand LRPs more available, Diego might allocate multiple instances of the same application to run simultaneously on different VMs, often spread across Availability Zones that serve users in different geographic regions.
Diego Auction process is repeated whenever new jobs need to be allocated to VMs. Each auction distributes a current batch of work, Tasks and LRPs, that can include newly created jobs, jobs left unallocated in the previous auction, and jobs left orphaned by failed VMs. Diego does not redistribute jobs that are already running on VMs. Only one auction can take place at a time, which prevents placement collisions.
Ordering the auction batch
Diego Auction algorithm allocates jobs to VMs to fulfill the following outcomes, in decreasing priority order:
Keep at least one instance of each LRP running.
Run all of the Tasks in the current batch.
Distribute as much of the total desired LRP load as possible over the remaining available VMs, by spreading multiple LRP instances broadly across VMs and their Availability Zones.
To achieve these outcomes, each auction begins with the Diego Auctioneer component arranging the batch jobs into a priority order. Some of these jobs might be duplicate instances of the same process that Diego needs to allocate for high-traffic LRPs to meet demand. The Auctioneer creates a list of multiple LRP instances based on the desired instance count configured for each process.
For more information, see the Step 2: Passing a request to the auctioneer process section of the Diego Components and Architecture topic.
For example, if the process LRP-A has a desired instance count of 3 and a memory load of 2, and process LRP-B has 2 desired instances and a load of 5, the Auctioneer creates a list of jobs for each process as follows:
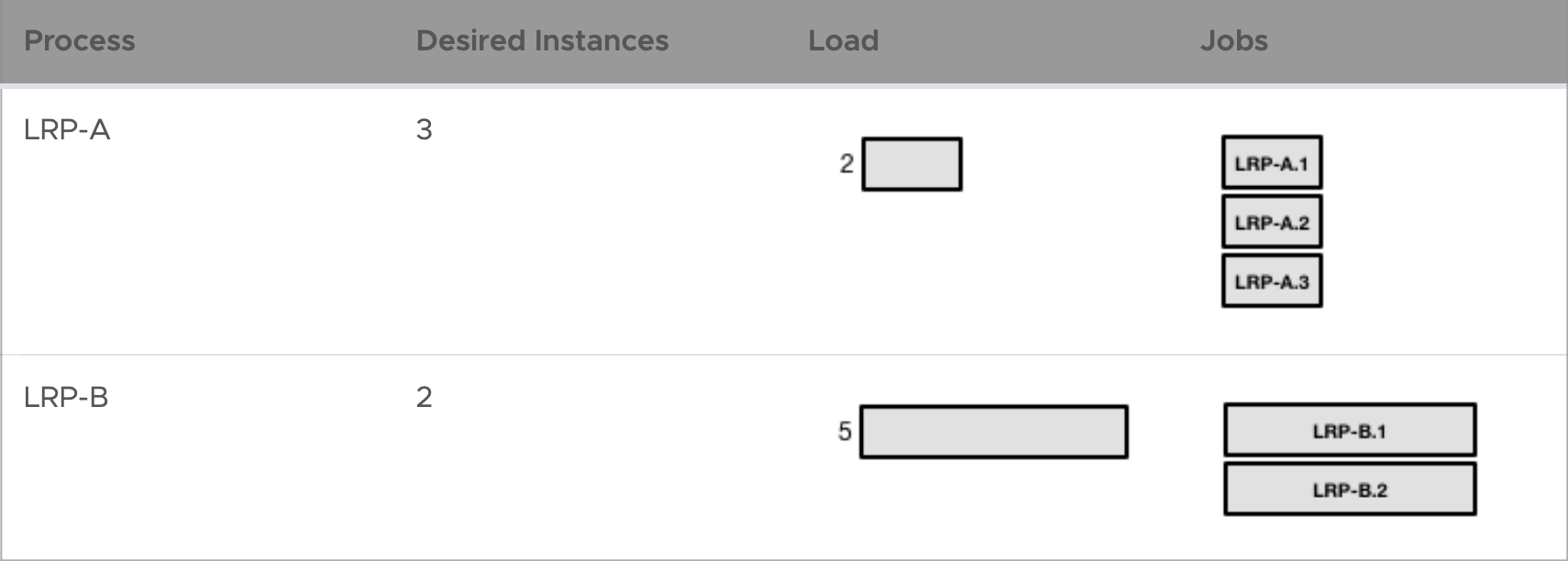
The Auctioneer then builds an ordered sequence of LRP instances by cycling through the list of LRPs in decreasing order of load. With each cycle, it adds another instance of each LRP to the sequence, until all desired instances of the LRP have been added. With the example above, the Auctioneer would order the LRPs like this:
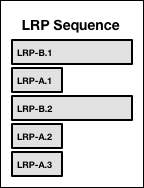
The Auctioneer then builds an ordered sequence for all jobs, both LRPs and Tasks. Reflecting the auction batch priority order, the first instances of LRPs are first priority. Tasks are next, in decreasing order of load. Duplicate LRP jobs come last.
Adding one-time Task-C (load = 4) and Task-D (load = 3) to the above example, the priority order becomes:
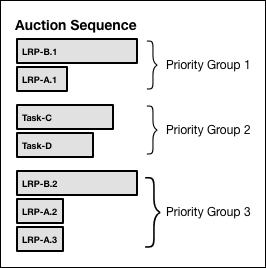
The previous diagram shows the following content:
Title: Auction Sequence
- Priority Group 1
- LRP-B.1 (wide box)
- LRP-A.1 (narrow box)
- Priority Group 2
- Task-C (medium-wide box)
- Task-D (narrower box)
- Priority Group 3
- LRP-B.2 (wide box)
- LRP-A.2 (narrow box)
- LRP-A.3 (narrow box)
- Priority Group 1
Auctioning the batch to the Diego Cells
With all jobs sorted in priority order, the Auctioneer allocates each in turn to one of the VMs. The process resembles an auction, where VMs “bid” with their suitability to run each job. Facilitating this process, each app VM has a resident Diego Cell that monitors and allocates the machine’s operation. The Diego Cell participates in the auction on behalf of the virtual machine that it runs on. For more information, see the Diego Components section of the Diego Components and Architecture topic.
Starting with the highest priority job in the ordered sequence, the Auctioneer polls all the Diego Cells on their fitness to run the currently-auctioned job.
Diego Cells “bid” to host each job according to the following priorities, in decreasing order:
Allocate all jobs only to Diego Cells that have the correct software stack to host them, and sufficient resources given their allocation so far during this auction.
Allocate LRP instances into Availability Zones that are not already hosting other instances of the same LRP.
Within each Availability Zone, allocate LRP instances to run on Diego Cells that are not already hosting other instances of the same LRP.
Allocate any job to the Diego Cell that has lightest load, from both the current auction and jobs it has been running already. In other words, distribute the total load evenly across all Diego Cells.
This example auction sequence has seven jobs: five LRP instances and two Tasks.
The following diagram shows how the Auctioneer might distribute this work across four Diego Cells running in two Availability Zones:
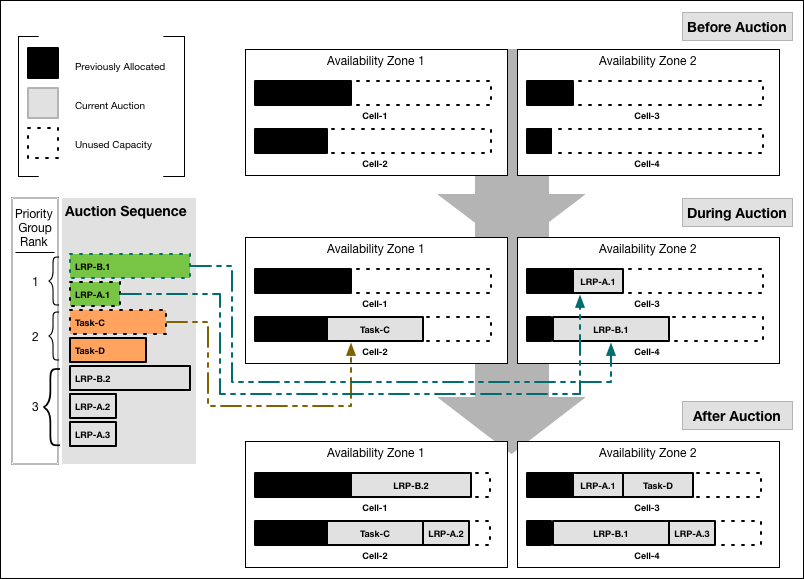
If the Auctioneer reaches the end of its sequence of jobs, having distributed all jobs to the Diego Cells, it submits requests to the Diego Cells to run their allotted work. If the Diego Cells run out of capacity to handle all jobs in the sequence, the Auctioneer carries the unallocated jobs over and merges them into the next auction batch, to be allocated in the next auction.
Triggering another auction
The Diego Auction process repeats to adapt a Cloud Foundry deployment to its changing workload. For example, the BBS initiates a new auction when it detects that the actual number of running instances of LRPs does not match the number desired. Diego’s BBS component monitors the number of instances of each LRP that are currently running. The BBS component periodically compares this number with the desired number of LRP instances, as configured by the user. If the actual number falls short of what is desired, the BBS triggers a new auction. In the case of a surplus of app instances, the BBS stops the extra instances and initiates another auction.
Cloud Controller also starts an auction whenever a Diego Cell fails. After any auction, if a Diego Cell responds to its work request with a message that it cannot perform the work after all, the Auctioneer carries the unallocated work over into the next batch. But if the Diego Cell fails to respond entirely, for example if its connection times out, the unresponsive Diego Cell might still be running its’ work. In this case, the Auctioneer does not automatically carry the Diego Cell’s work over to the next batch. Instead, the Auctioneer defers to the BBS to continue monitoring the states of the Diego Cells, and to reassign unassigned work later if needed.
Create a pull request or raise an issue on the source for this page in GitHub